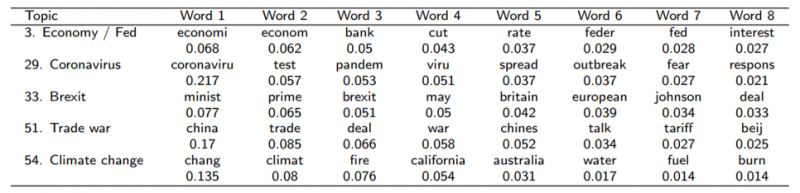
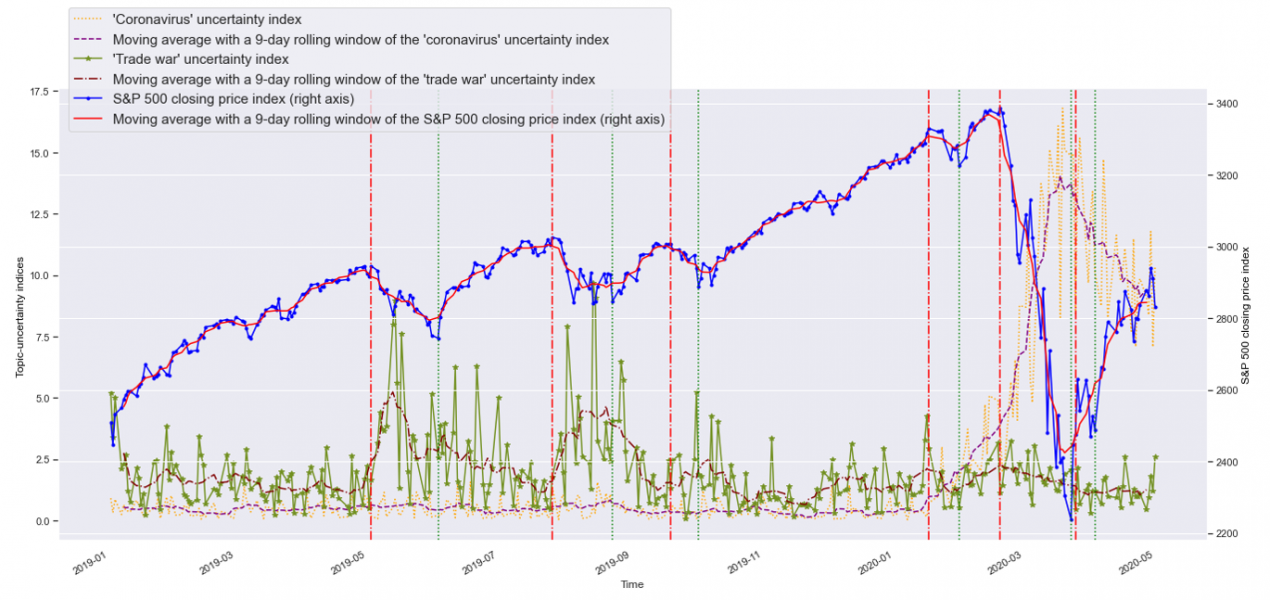
The material presented here is based on “Moreno Pe rez, C., Minozzo, M. (2022). Natural language processing and financial markets: semi-supervised modelling of coronavirus and economic news. Documentos de Trabajo, Banco de España, 2228.” The opinions and analyses in this Policy Brief are the responsibility of the authors and, therefore, do not necessarily coincide with those of the Banco de España or the Eurosystem.