
Since the 2007-2008 financial crisis, global regulatory regimes and reporting have improved significantly, and the Basel reforms were broadly deemed sufficient. Coupled with the high costs for financial institutions (FI), the widespread easing of regulatory requirements and additional ad hoc requests due to the COVID-19 crisis highlight that the current regulatory reporting model is not sustainable enough, especially in times of intense stress.
The authors of this paper present case studies on how selected jurisdictions have attempted to improve granular data collection and reporting. Furthermore, this paper outlines an agile concept, called RegOps, for the complete digitalization of regulatory reporting, which maximizes operational efficiency and presents a transformation scenario on how to shift to this novel model.
The decade of the 2010s saw the implementation of Basel III reforms (BIS 2011) to cope with fallout of the 2007/2008 financial crisis. With the official end of the post-2007 crisis agenda (BIS 2020c) and the Covid-19 pandemic as well as the ensuing economic crisis, we are at a perfect point to evaluate banking regulation and the corresponding banking regulatory reporting system.
When looking at the results of the Basel III reform (BIS 2019) regarding its performance, one can observe a mixed picture. For one, many of the ideas manifested in the Basel reforms and its national and supranational implementations were highly successful. Especially higher capital requirements and increased resilience of financial markets have proven to be a stabilizing factor for the world’s economies instead of financial institutions being the primary source of instability. Overall, the reforms had a positive influence on the well-being of the world economy.
On the other hand, several major deficiencies of banking regulation became visible or are now prominently in the focus of all involved stakeholders in the financial market. Most remaining shortcomings are interestingly found not in the principal ideas and concepts of the regulatory reforms but their functional, technical, and organizational implementation. To find approaches to overcome these shortcomings, the authors propose the “RegOps” approach, a regulatory reporting framework that combines an integrated data flow, a common processing of standardized, granular datasets based on a big data-enabled platform for computation and analysis. This model was also successfully implemented in a Proof-of-Concept and proved to deliver all requirements conceptually.
The authors would like to embark on this journey by citing Benoî t Coeure (2020), Head of the BIS Innovation Hub: “The benefits and opportunities of regtech and suptech for regulated entities and supervisory authorities to improve efficiency, reduce manual processes and make effective use of data are enormous. As they are more widely adopted, these technologies can enhance diligence and vigilance in risk monitoring and management in real time, improving the resilience and stability of the broader financial system.
Please note that this paper is a short version of our full RegOps paper, and we will redirect you in certain passages to the comprehensive version for a more complete insight. You can find the full paper here.
The first major deficiency is the generally low application of innovative technology in the fields of digitization and modern computing in the banking regulatory reporting regime. In most regulatory frameworks in global jurisdictions, regulatory data flow still happens in a quasi-manual, template-based fashion. This means that the mere automatization of manual, printed, or handwritten reporting processes of aggregated data, which was the main activity in the past years, is not enough. The digitalization of regulatory reporting does not only mean changing technology but also requires rethinking the whole process, from the beginning of data generation within banks throughout the entire processing chain to the regulators and analysts. Only a few jurisdictions have started the journey thinking regulation anew and leveraging the possibilities of new technologies like artificial intelligence (AI), application programming interfaces (API), big data, the cloud, high-performance computing, and blockchain/distributed ledger technologies (DLT). Many of these technologies, which were just mere buzzwords a few years ago, have meanwhile matured far enough to contribute to and enable new approaches to banking regulation, and especially regulatory reporting. What is necessary for regulators is to understand how to build a functioning architecture by combining innovative technology and transforming existing frameworks in a future-ready state.
These technologies could also help to topple the second point, the high cost of regulation and regulatory reporting. Estimations of the cost of regulatory reporting vary wildly, yet all indicate very high costs for financial institutions. McKinsey estimates that the annual cost for regulatory reporting of UK banks is 2bn – 4.5bn GBP (Van Steenis, 2019). A commission staff working document estimated 4bn EUR for the European Union (European Commission, 2020), while a study by Chartis & BearingPoint estimated the cost of compliance in the EU and the USA for the full scope of risk data aggregation and regulatory reporting to be approximately 70bn USD (Chartis and BearingPoint, 2018).
While banking regulation has become more effective over the last decade, it is clear that the marginal use of an ever-increasing set of template-based regulatory requirements is strongly decreasing; the main impediments being the limited insight and flexibility of the aggregated data reported. Also, it becomes clear that while technology could significantly reduce costs, it currently cannot be deployed efficiently because of a lack of common standards in data models and processing. The financial markets would need a common standard to describe regulatory data requirements and the corresponding regulatory logic processing before leveraging large amounts of data with modern technology. To a large extent, the current high costs in regulatory data generation for institutions are rooted in the necessity to leverage the same information artefacts over and over again for different non-aligned regulatory reporting regimes with myriads of templates (prudential, national, statistical, granular, resolution reporting) with often very similar, but slightly differing definitions. Institutions’ costs could be sharply decreased if data would only be requested once in a granular, standardized, aligned, structured fashion, and processed with common regulatory logic while supervisors would have better data quality, much more agile access to data and a far increased flexibility to get the answers to the questions they are truly interested in. Improved, common forensic insight in risk concentration would optimally lead to reduced losses for banks and more insight for regulators concurrently. Standardized granular data models and processing logic would also boost the use of new technology and strongly decrease implementation costs and costs of change, which are currently one of the main hurdles of technology adoption. However, common standards require finding governance models between the different stakeholders within the financial markets on the one hand, and between the financial market stakeholders and the regulatory authorities, on the other hand.
The third shortcoming of the current regulatory regimes is the lack of operational excellence, which became apparent via several high-profile failures in recent years, such as the hidden derivative losses at Banca Monte dei Paschi di Siena (Sanderson and Crow, 2019) and the Wirecard scandal (McCrum, 2020). For one, offsite supervisory overview is still limited due to the nature of the collected data. Aggregated and template-based reporting is conceptually more prone to data correction or even manipulation. Fully granular, automatically pushed, end-to-end integrated data delivery, possibly accompanied by other trust ensuring technologies like blockchain, could strongly improve trust and operational stability for data reporting and could data manipulation virtually impossible or prohibitively expensive. Another problem is the lack of quality, timeliness, and inter-entity matching, meaning the complementary fit of the two datasets, representing two sides of the same transaction, which could be strongly improved using granular, end-to-end delivery of granular data.
On the other hand, the Covid-19 crisis as the first real test of the new regulatory regime showed that while many of the Basel reforms in general had a positive impact, the regulatory reporting component proved difficult to operate. The paradox situation arose that many jurisdictions issued moratoria on new reporting regulations or eased reporting obligations in exact the crisis situations where ample information is critical for regulators to take informed decisions. Even if eased obligations primarily concerned less important information for crises management, we could see, that the implementation of urgently needed new data requirements lasts many months (e.g. data on moratoria or state guarantees), a timing, which is definitely too slow.
The following part aims to outline a few main elements needed to improve the current regulatory reporting regimes in the authors’ view. A stock-taking exercise will follow to see how certain notable jurisdictions found solutions to address these needed elements, and why they were successful to introduce them. The following features are missing in current regulatory reporting regimes:
As stated above this version is a shortened version of the original paper. Please refer to the complete version for insights into currently productive notable case studies of modernized regulatory reporting regimes:
RegOps is closely connected to the term DevOps (a portmanteau of development and operation), known from software development and seen as the answer to the shortcomings of the waterfall model. The waterfall model, as a traditional plan-driven approach to software development, has been around for decades. Critics argue that the waterfall model lacks the flexibility to accommodate customer changes and that its linear stages to software development are not people-centered, do not encourage customer collaboration and leave no room for creativity nor innovation. To improve software development, individuals have adopted methodologies that focus on customer collaboration, continuous delivery, constant feedback and communication between developers, customers, and users while delivering software incrementally in small releases. These methodologies have led many individuals to become advocates of an agile way of thinking. Gartner declared that “DevOps movement was born of the need to improve the agility of IT service delivery and emphasizes people and culture and seeks to improve collaboration between development and operations teams while seeking to remove the unnecessary impediments to service and application delivery by making use of agile and lean concepts” (Wurster et al., 2013).
For this reason, DevOps can be considered as the integration and application of different software development methodologies, operational processes, and social psychological beliefs for transforming IT service delivery. From this perspective, DevOps is a new way of thinking, a spirit, a philosophy for transforming organizations. Gartner analysts declare that DevOps “… is a culture shift designed to improve quality of solutions that are business-oriented and rapidly evolving and can be easily molded to today’s needs” (Wurster et al., 2013).
Regulation has been developed (conceptualized, drafted, released) and rolled out according to the waterfall model over the decades, leading to disastrous, purely reactive time-to-market and offering hardly any flexibility in embracing regulatory change. Most of all, it created enormous costs to regulators but, more importantly, to the financial services industry. Similar to DevOps, RegOps improves the way regulators and regulated entities interact: collaboration, continuous delivery, constant feedback and communication between regulators and the regulated, while delivering regulatory change incrementally in small releases without affecting the whole system.
RegOps is defined as an approach to systematically change how regulation is developed and deployed and how data is exchanged between regulators and regulated using push and pull approaches. With standardization and industrialization, RegOps provides a framework and infrastructure to regulators worldwide to collect data efficiently and flexibly from the regulated markets. With the use of modern technology and proven standardization artefacts, RegOps allows regulators to arrive closer to the dream of RegTech from Andy Haldane (Bank of England) in 2014: “I have a dream. It is futuristic, but realistic. It involves a Star Trek chair and a bank of monitors. It would involve tracking the global flow of funds in close to real time (from a Star Trek chair using a bank of monitors), in much the same way as happens with global weather systems and global internet traffic. Its centerpiece would be a global map of financial flows, charting spill-overs and correlations” (Haldane, 2014). With RegOps, regulation and reporting are not a top-down process based on macroeconomic risk considerations, which are transformed into standardized regulatory approaches, definitions, and later implemented in fixed, low insight-giving regulatory templates. Instead, the proposition is to start regulation as a bottom-up process focusing on regulatory micro definitions of standardized data fields and models on the granular dataset and data information level, which can then be flexibly used for any macro-regulatory requirement, such as calculations for different and even changing macro regulatory approaches based on the granular standardized data.
In this section a proposal for the future of regulatory reporting is outlined which not only comprises all the features mentioned earlier, but which could also be deployed in reasonable timeframe due to the availability of its three basic elements. These elements are:
Please refer to the full version of the paper for detailed insights into each of these points.
4.1 The RegOps Model
When we combine these elements, we can see a system where regulatory data is directly sourced from a highly detailed, complete, and fully granular standardized data model from every single institution. This data can then be accessed by a standardized logic to be imported, processed, and returned in standardized and ad-hoc formats for the regulator. The proposal would streamline the reporting stream as far as possible and largely solves the issues of system breaks in the current regulatory reporting flow. Furthermore, it would solve the issues of standardization for the data model and the data processing logic to ensure the highest possible quality and comparability.
An interesting side effect is that this model will virtually end the need for regulatory change on the side of financial institutions after a few iterations, as there is only a finite number of sensible information artefacts and data fields to be added to such a granular data model. The regulator can then flexibly build new regulatory templates without action required by the financial market. This is also confirmed by the authors’ experience of operating granular data model-based regulatory reporting approaches.
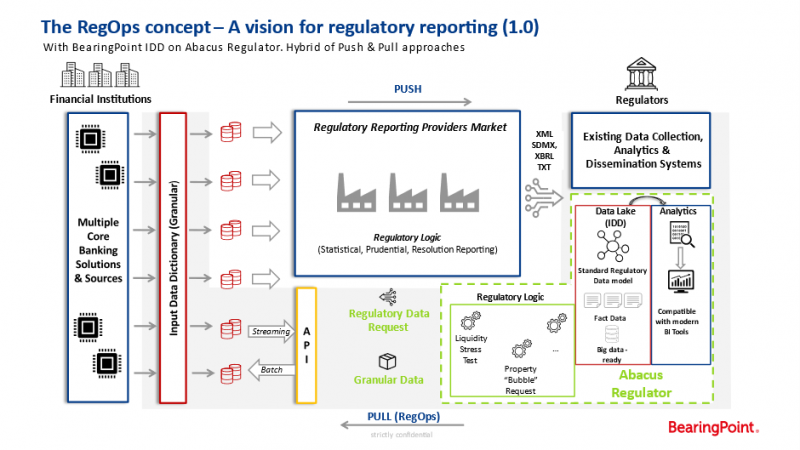
The pull-based model could be gradually phased in to gain experience with granular data and give time to adopt regulation and legislation towards the new architectur while keeping the existing regulatory reporting infrastructure (push approach) in place to enable a smooth transition for all involved parties. If the model yields the envisaged benefits, the legacy push-based infrastructure could be migrated gradually to the new pull model, resulting in a scenario described in the diagram below.
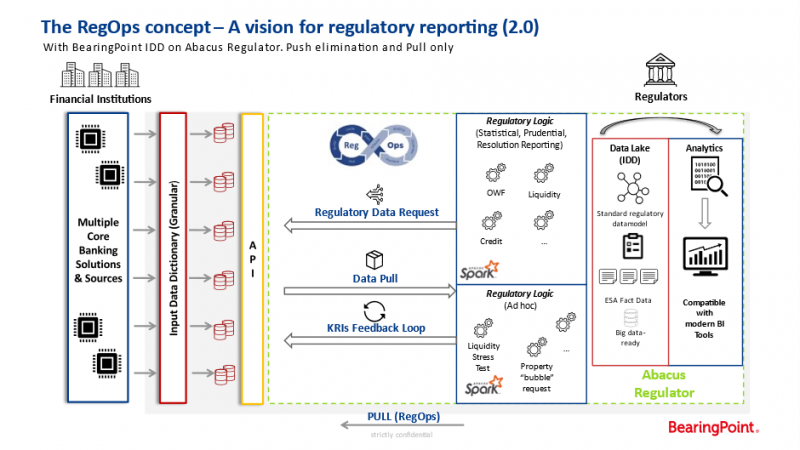
Thus, we would see a natural shift of regulatory development from “waterfall supervision” to “agile supervision.” This model would not only strongly increase the quality, timeliness, completeness, and transparency of regulatory reporting but also concurrently greatly reduce the cost and efforts for regulatory reporting for the affected financial institutions.
4.4.1 RegOps Proof-of-Concept “G20 / BIS Techsprint 2020”
BearingPoint RegTech participated in the G20 / BIS Techsprint 2020 with the RegOps model and developed a fully functional prototype. The PoC was deployed by reusing existing software stacks and regulatory contents in a completely new manner. BearingPoint RegTech built a fully working demo version within a five-week time frame. The solution was shortlisted by the G20 / BIS Techsprint 2020 judges panel for the finalist round in September 2020 (BIS 2020c).
The prototype was able to prove the feasibility of the model and to deliver a functioning prototype exemplifying the application of all three components of RegOps, namely a standardized data model & processing logic, a end-to-end integrated data flow via API, and a big data-enabled regulatory platform for data collection and analysis.
Please refer to the full version of the paper for further insights into the G20 prototype.
The RegOps approach is a novel approach to tackle the two most urgent issues in regulatory reporting today: the lack of quality of regulatory reporting data and the concurrently high, unsustainable efforts and costs of financial institutions to produce this data. These issues are rooted in a lack of granular data delivery, a standardized, common data model and processing logic, and end-to-end integrated data flow. These are also the main inhibitors for the application of modern technology to the current regulatory reporting regimes and were confirmed by an FSB study when mapping to the expected benefits of regulators.
This paper identified core prerequisite features that a new regulatory reporting system needs to overcome the current issues. These are:
The paper has demonstrated that many of these problems and features were already partially addressed via various approaches and initiatives by regulators, financial institutions, and solution providers worldwide and have shown that they are able to deliver positive results not only in theory but also in practice.
Furthermore, the authors have shown how an underlying IT architecture of such a system could be constructed adhering to the principles of modern data infrastructure architectures (Bornstein, Casado & Li, 2020). The system would need to deploy standardized databases, which are the source systems for the regulatory system. These standardized source database systems require a common data model to incorporate a data dictionary, the data model itself, and a metadata model. This data model would need to apply to all kinds of supervised institutions and business models. Minimally, this model would need to be suitable for the regulatory requirements of the respective jurisdictions but should be designed, if possible, with supranational and international applicability in mind. The common root for such an integrated data model could be either a data model completely developed by the regulatory authorities, an extension of existing industry data models, or a hybrid of both. The authors argue that a hybrid approach that incorporates specific industry standards will most likely be the best approach for many jurisdictions where granular, regulatory data standards do not exist or where a focus lies on international and supranational applicability.
The second part of the IT architecture would be an API or multi-API setup able to route data from the granular, standardized regulatory source databases of the individual financial institutions to the database of the SupTech solution, which is deployed by the supervisory authorities. This API or multi-API setup will act as safe communication points and offer secure channels between the parties. Furthermore, API systems should deploy standardized, common functional logic for transformations and allocations of data accessible in code alongside the legal prose via common code repository applications. The API infrastructure could distribute calculations, transformations, or consistency/quality checks decentrally, which are too computing intense for a supervisor’s system. These operations would be stored in so-called functional units, which should be stable and publicly transparent for regular reporting requirements or non-public and flexible for individual ad-hoc requests. The API could also act as a buffer layer between the regulator and the financial institutions and could mitigate certain legal aspects concerning direct regulatory access to the databases of financial institutions.
The third component of the model is a big data-enabled SupTech platform deployed by the regulator to collect, store, and analyze the granular data reported by the financial institutions. This platform would need to be developed natively to handle big data volumes and respective tasks. It would also need to give the supervisors a toolset to analyze the data in a performant manner. The paper provides insight into which types of technology frameworks could be useful in this context. Furthermore, the SupTech solution would need to give the regulators the possibility to define standard or ad-hoc calculations or data requests. These so-called functional units can be processed by the API on the financial institutions’ databases.
The authors argue that the first iteration of the proposed model is feasible with today’s technology, available data standards, and current governance setups. For financial jurisdictions with common data standards, implementation could start instantly for a relatively low cost. It is realistic for other jurisdictions to envision an implementation effort of about 1-2 years for initial results if a common data model based on existing standards can be quickly agreed upon. Possible transformation scenarios give regulators and financial institutions ample time to learn about moving to completely granular data delivery by first applying the new system to experimental ad-hoc reporting (RegOps V1.0). Then they can begin to onboard the first legally binding reporting frameworks (RegOps V1.X) until eventually shifting all reporting requirements to the new system (RegOps V2.0). A specific timeframe for transforming the system is also needed to build up IT capabilities and train staff in financial institutions and regulatory authorities to handle and analyze granular regulatory reporting data.
Such a regulatory reporting system would mean a complete digitalization of the regulatory value-chain and solve many of today’s problems. The shift from a regulation-driven to data-driven regulatory reporting is also a perfect base layer for the application of emerging technologies like blockchain (Münch and Bellon, 2020) (Regulation execution, data collection, and transmission), artificial intelligence (data validation, processing, and analysis), cloud computing (storing, processing) or quantum computing (calculations). Furthermore, a shift to a data-driven regulatory model would fit and facilitate the digitalization push, which can be observed for many data sources in issuance, trading, credits and loans, payments, KYC/AML, accounting, and other finance-related activities.
The authors urge regulatory authorities and supervisors to test new approaches to regulatory reporting and recommend conducting trials and proof-of-concept studies to validate approaches such as RegOps further. The studies should focus on finding a balance between what is technically possible and what is needed from a functional and governmental point of view for regulatory reporting. These trials should include all relevant stakeholders of the financial markets and not only regulatory authorities. It will also be highly beneficial if these trials are coordinated internationally, and information on the results are shared within the supervisory and financial market community. In a first iteration, the concept was shortlisted by the G20 / BIS Techsprint 2020 as a finalist solution for the future of regulatory reporting use case. It was subsequently implemented in a successful PoC project (BIS 2020c). The intention is to conduct further PoCs to learn about the implications of operating under the RegOps approach.
As previously stated, this paper is a shortened version of the original RegOps paper, and the authors would like to invite to read the full version to find about more about the RegOps concept.
Bank for International Settlements, (2011). Basel III: a global regulatory framework for more resilient banks and banking systems. https://www.bis.org/publ/bcbs189.htm [Accessed 9th November 2020]
Bank for International Settlements, (2020). Governors and Heads of Supervision commit to ongoing coordinated approach to mitigate Covid-19 risks to the global banking system and endorse future direction of Basel Committee work. https://www.bis.org/press/p201130.htm [Accessed 10th December 2020]
Bank for International Settlements, (2020b). The Basel Framework. https://www.bis.org/basel_framework/index.htm [Accessed 12th August 2020]
Bank for International Settlements, (2020c). Saudi G20 Presidency and BIS Innovation Hub update on the progress made in the G20 TechSprint initiative. https://www.bis.org/press/p200810.htm [Accessed 23th September 2020]
Bank of England, (2020). Discussion paper – Transforming data collection from the UK financial sector. https://www.bankofengland.co.uk/paper/2020/transforming-data-collection-from-the-uk-financial-sector [Accessed 10th February 2020]
Bornstein, M., Casado, M. and Li, J., (2020). Emerging Architectures for Modern Data Infrastructure. https://a16z.com/2020/10/15/the-emerging-architectures-for-modern-data-infrastructure/ [Accessed 6th November 2020]
Cœuré, Benoît, (2020). Leveraging technology to support supervision: challenges and collaborative solutions. 19th August 2020, Peterson Institute for International Finance. https://www.bis.org/speeches/sp200819.pdf [Accessed 1st October 2020]
Chartis and BearingPoint, (2018). Counting and Cutting the Cost of Compliance- How to accurately assess the cost of Risk Data Aggregation and Regulatory Reporting. https://www.reg.tech/files/Chartis_COC_Position-Paper.pdf?download=0&item=7197 [Accessed 24th September 2020]
Haldane, A., G., (2014). Managing global finance as a system. Speech at Maxwell Fry Annual Global Finance Lecture, Birmingham University.
https://www.bankofengland.co.uk/-/media/boe/files/speech/2014/managing-global-finance-as-a-system.pdf?la=en&hash=93BF6D650AAE5D055618D2D2DBC5870DC0580FA7 [Accessed 22nd July 2020]
McCrum, D., (2020). Wirecard and me: Dan McCrum on exposing a criminal enterprise. https://www.ft.com/content/745e34a1-0ca7-432c-b062-950c20e41f03 [Accessed 29th September 2020]
Münch, D. and Bellon, N., (2020). DLT-Based Regulatory Reporting – A game changer for the regulatory regime? SUERF Policy Note, No 123. DLT-Based Regulatory Reporting – A game changer for the regulatory regime? [Accessed 22nd July 2020]
Sanderson, R. and Crow, D., (2019). Jail terms for 13 bankers over Monte Paschi scandal. https://www.ft.com/content/54ace10a-023e-11ea-b7bc-f3fa4e77dd47 [Accessed 29th September 2020]
Van Steenis, H., (2019). Future of Finance Review on the Outlook for the UK Financial System: What It Means for the Bank of England. Future of Finance Report, Bank of England, https://www.bankofengland.co.uk/report/2019/future-of-finance [Accessed 15th July 2020]
Wurster, L., Colville, R., Haight, C., Tripathi, S. and Rastogi, A. (2013). Emerging technology analysis: DevOps a culture shift not a technology. Gartner. https://www.gartner.com/en/documents/2571419/emerging-technology-analysis-devops-a-culture-shift-not- [Accessed 15th September 2020]
Martina Drvar, Vice Governor, Croatian National Bank and Member of the European Banking Authority Management Board − Johannes Turner, Director Statistics Department, Oesterreichische Nationalbank (OeNB) − Maciej Piechocki, Member of Management Board, BearingPoint RegTech − Eric Stiegeler, Senior Manager, BearingPoint RegTech − Daniel Münch, Team Lead Emerging Technologies, BearingPoint RegTech.




