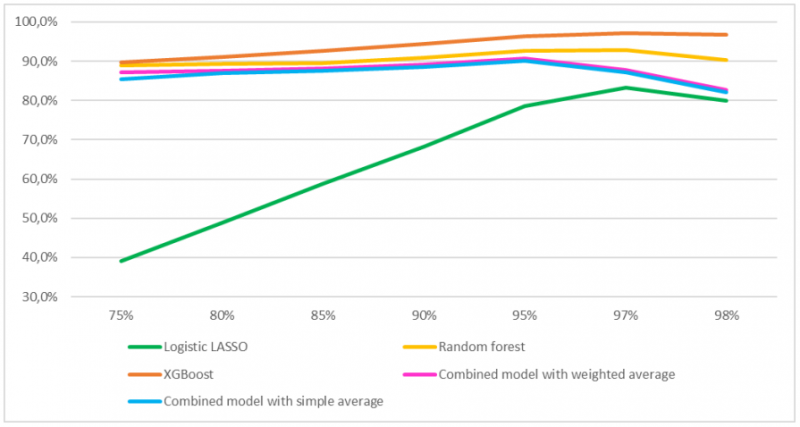
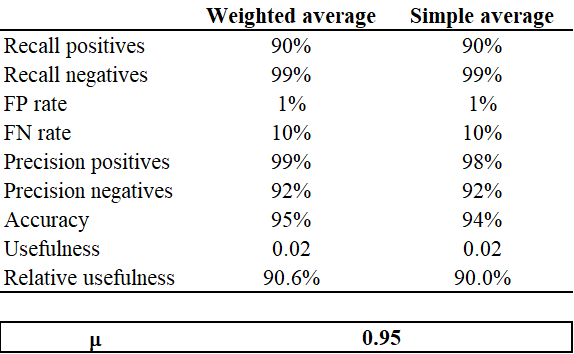
References
Bank for International Settlement (2017). Designing frameworks for central bank liquidity assistance: addressing new challenges. CGFS Papers number 58.
Betz F., S. Oprică, T. A. Peltonen and P. Sarlin (2013). Predicting Distress in European Banks. ECB Working Paper Series number 1597.
Breiman L. (2001). Random forests. Machine Learning, 45, 5–32, 2001.
Chen T. and C. Guestrin (2016). XGBoost: a scalable tree boosting system. 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785-794.
Diamond D. W. and Dybvig P.H. (1983). Bank Runs, Deposit Insurance, and Liquidity. The Journal of Political Economy, Vol. 91, No. 3, pp. 401-419.
Dobler M., S. Gray, D. Murphy and B. Radzewicz-Bak (2016). The Lender of Last Resort Function after the Global Financial Crisis. IMF Working Paper WP/16/10.
Drudi, M. L. and Nobili, S. (2021). A Liquidity Risk Early Warning Indicator for Italian Banks: A Machine Learning Approach. Bank of Italy Temi di Discussione (Working Paper) No. 1337.
Holopainen M. and P. Sarlin (2017). Toward Robust Early-Warning Models: A Horse Race, Ensembles and Model Uncertainty. Quantitative Finance 17 (12), 1-31.
Sarlin P. (2013). On biologically inspired predictions of the global financial crisis. Neural Computing and Applications, 2013, 24 (3 – 4), 663 – 673.
Tibshirani R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society (Series B), 58(1):267 – 288.