
We have used a collection of central bank speeches on CBDCs collected at Auer et al (2020)1. It contains 331 central bank speeches that explicitly mention CBDC from 2016 to 2022, from 44 different geographic areas. The collection of texts also includes the authors’ expert judgment evaluation of the text’s sentiment about CBDC. This will allow us to compare the expert’s opinion (BIS2 labeled data from now on) with that of the NLP methods.
Compute the sentiment score towards central bank digital currencies, measured between -1 and 1, of a given text. The response should be just a float number, no text. The text is as follows: […]3

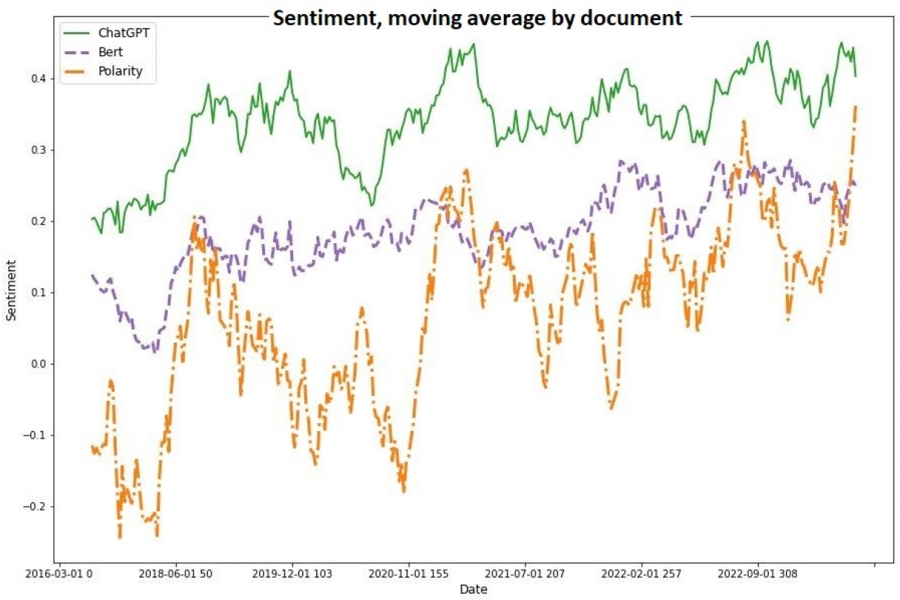
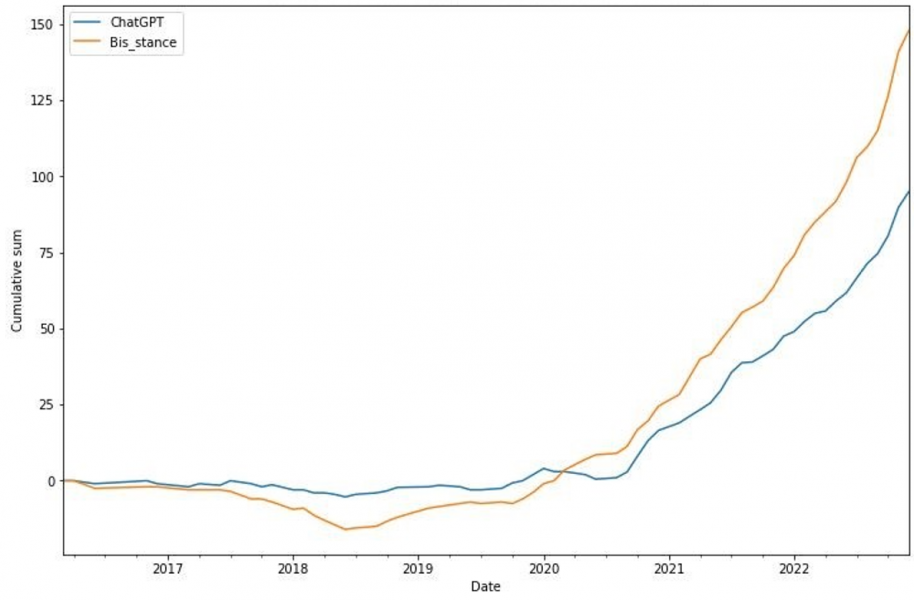
Database updated up to January 2023.
Bank for International Settlements.
We have performed robustness analysis with different prompts. At the time of writing, the best version available in ChatGPT API was GPT-3.5, with a limitation of 4,000 tokens per prompt.
A token is a single unit of text, like words, numbers, or punctuation marks, separated by white space or other delimiters.

