References
Cavallo, A. 2013. Online and official price indexes: Measuring Argentina’s inflation. Journal of Monetary Economics 60 (2). 152–165.
Cavallo, A. 2018. Scraped Data and Sticky Prices. Review of Economics and Statistics 100 (2018). 105–119.
Cavallo, A. and R. Rigobon. 2016. The Billion Prices Project: Using Online Prices for Measurement and Research. Journal of Economic Perspectives 30 (2). 151–78.
Dedola, L., C. Osbat and T. Reinelt. 2022. Tax thy neighbour: Corporate tax pass-through into downstream consumer prices in a monetary union. ECB Working Paper Series, forthcoming.
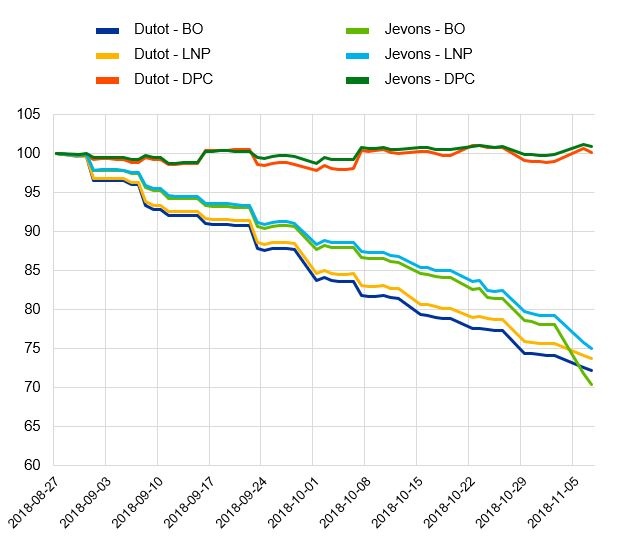
Goldhammer, B., L. Henkel and M. Osiewicz. 2019. Bias related to the Bridged-overlap- and Link-to-Show-No-Price-Change Method. Poster presented at the 16th Meeting of the Ottawa Group on Price Indices, Rio de Janeiro. 2019.
Lehmann, E., A. Simonyi, L. Henkel and J. Franke. 2020. Bilingual Transfer Learning for Online Product Classification. In: Proceedings of Workshop on Natural Language Processing in E-Commerce. 21–31. Barcelona, Spain. Association for Computational Linguistics.
Macias, P., D. Stelmasiak and K. Szafranek. 2022. Nowcasting food inflation with a massive amount of online prices. International Journal of Forecasting.
Powell, B., G. Nason, D. Elliott, M. Mayhew, J. Davies and J. Winton. 2018. Tracking and modelling prices using web‐scraped price microdata: towards automated daily consumer price index forecasting. Journal of the Royal
Statistical Society Series A. Royal Statistical Society, vol. 181(3). 737–756.