
Applications of methods from Natural Language Processing have increasingly been used within economics to shed new light on key questions of interest. Within this policy brief, we argue that though methods to quantify topic and tone have now been widely applied, we know little about the temporal orientation of text and speech in economics. We outline a method for measuring this temporal component, suitable for wide application in future research. Using the Federal Reserve Greenbook information as a cross-check, we find that our measure accurately identifies temporal references in text. In addition, using a large dataset of policymaker speeches from the ECB, Federal Reserve, IMF and other EU Institutions, we unveil some stylized facts about the ways in which policymakers talk about time.
An important way to expand understanding of economic questions is to bring new data to bear on our research. The integration of Natural Language Processing (NLP) methods into economics has allowed us to incorporate insights from textual data, and even other unstructured data such as sound and images. In this endeavour, we doubly benefit from increased computational power and the vast repositories of text made widely available in the digital age. Influential text applications have studied the impact of policymaker communication on broader economic outcomes, and the usefulness of news sources for nowcasting, for example. To date, most of the NLP studies in economics have concentrated on quantifying the Topic and/or the Tone of the text. We refer to these as the “Two T’s” of textual data. We argue that the temporal orientation of text has been understudied to date in the economic literature, and contribute by quantifying the “Third T”, Time.
Methods to quantify the topic of given documents have now been widely applied across social sciences. While approaches based on simple word-counts have proved fruitful, many methods exist to treat text as the outcome of a data generating process, which can be parameterized and estimated. A frequently used approach of this type is the Latent Dirichlet Allocation (LDA) methodology of Blei, Ng and Jordan (2003). A number of papers within economics have used such methodologies, for example Hansen and McMahon (2016), Azqueta-Gavaldon (2017), Hansen, McMahon and Prat (2018) and Istrefi, Odendahl and Sestieri (2021).
Methods focused on establishing tone are concerned with measuring the semantic orientation of text; in other words, they measure how “positive” or “negative” it is. In the case of central bank communication, one could use these methods to quantify how “hawkish” or “dovish” the text is. These approaches can involve applying dictionaries of key words, such as those of Stone et al. (1966) or Nielsen (2011), or could apply Machine Learning techniques such as random forests, support vector machines or neural networks. Measures of tone have now been widely used within economics to date, in studies such as in Apel, Blix Grimaldi and Hull (2022), Renault (2017), Parle (2022) and Schmelling and Wagner (2019).
Our work, however, concentrates primarily on the “Third T” of text analysis: Time. This is concerned with measuring the temporal orientation of a piece of text – is the speaker talking about the past, present or future? To date in the economics literature, this has been the least studied of these textual dimensions. Given a means to quantify the temporal orientation of text in economics, a multitude of interesting research questions would become tractable. In a monetary policy setting, one could determine the relative weight the policymaker places on realized data versus their model projections, or one could examine the horizon into the future that the policymaker is discussing, and how this varies with the economic environment.
In a recent study1, we synthesize a number of existing methods to identify and quantify temporal statements from the portion of the NLP literature devoted to such problems. First, we use the SUTime method of Chang and Manning (2012) – a “temporal tagger” that uses a rules-based approach to tag references to time. SUTime searches strings of text for numerical references (e.g., “June 2023”) and categorical references (e.g., “in the future”, “currently”). Knowing the date of the text’s publication allows the algorithm to decode references such as “yesterday” or “in two months’ time”. The output is a set of past, present and future tags of both categorical and numerical type.2
While SUTime has a broad library of dates, we make a number of additions to better suit the lexicon of policymakers and economists. First, we add important economic dates such as the “Great Depression”, since these are commonly referred to and would have clear temporal meaning to the audience. Second, we broaden the terms used in the categorical tagger by adding economic phrases about time, such as “short-term” and “long-run”. Finally, we take care to remove academic citations, and references to concepts such as “long-term debt”, since these are largely uninformative for our purposes.
The second method we use is the Tense, Mood, Voice (TMV) algorithm of Ramm et al. (2017). This allows us to extract temporal information from the grammar of the sentences in the text. TMV uses a rules-based approach to identify the tense of a verbal complex3, returning output as a past, present or future tense tag. We expand the ruleset of TMV to address specific ways in which economic policymakers speak. For example, a policymaker might describe their future expectations for a key variable solely through using the present tense “we expect”. We modify the algorithm to identify such expressions as being references to the future.
We develop a method to apply both SUTime and TMV to text, allowing us to tag multiple forms of temporal reference in a given document and to identify broad categories of past, present and future. Figure 1 shows an example of applying the algorithm to two portions of text from the ECB in 2019. Blue references are future-oriented, while orange references are past-oriented. The tags arise from both SUTime (numerical and categorical) and TMV (tense4).
Figure 1: Sample SUTime and TMV output

Notes: Phrases marked Numerical are tagged as future/past using the SUTime tool. Phrases marked Categorical are tagged using the SUTime tool, with an additional bespoke dictionary of central-banking-specific future words (for example, “medium-run”). Phrases marked with Tense are tagged as future/past tense using the TMV tool. Phrases marked with Tense* are tagged as present tense using the TMV tool, but coded as future using a bespoke dictionary of present tense phrases that evoke future considerations, designed for use with central bank communications (for example, “expect”, “foresee”).
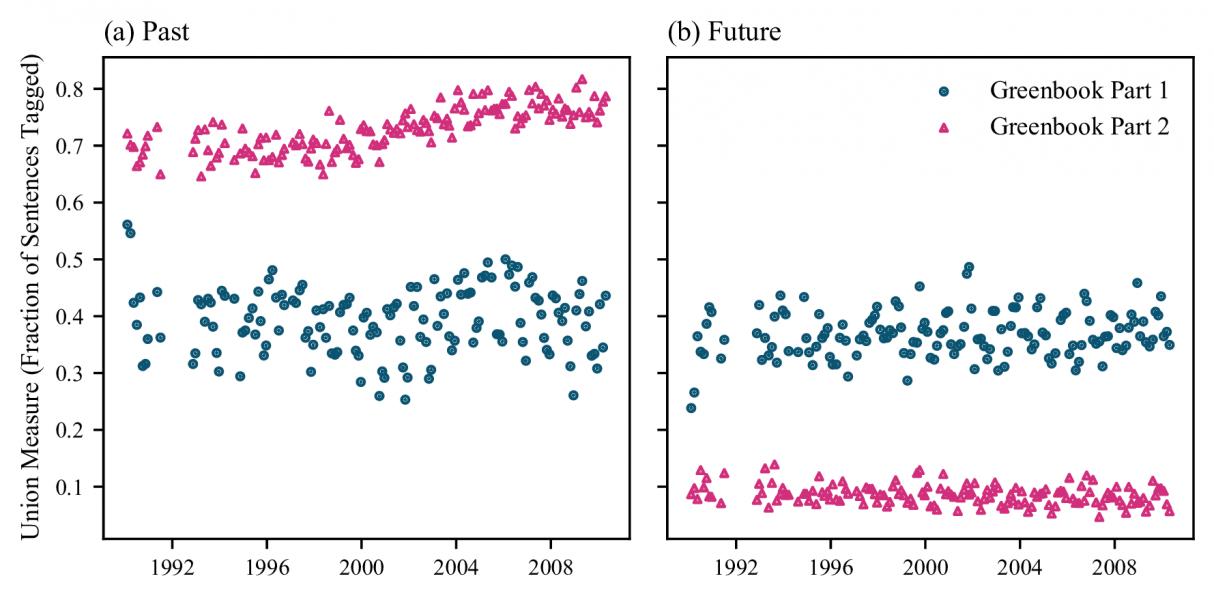
We use the output of the algorithm to create a “union measure” of the temporality of policymaker speeches. This is an aggregate measure of temporality looking across all tag types. Figure 2 shows the document-level values of the union measure of temporality from applying the algorithm to a set of Federal Reserve Greenbooks (supporting material for Federal Open Market Committee meetings). The Greenbooks are split into two parts – the first is about the Summary and Outlook (a combination of past and future) while the second is about “Recent Developments” (mainly about the past). Our algorithm indeed finds that Greenbook Part 1 is a mixture of past and future, while Part 2 is heavily weighted toward the past. Our algorithm thus correctly identifies Time in the text. For more detail on an application of our algorithm to monetary policy communication from the ECB and the Fed, see Byrne et al. (2023a).
Figure 2: Validation of our union measure of temporality
Applying the algorithm to policymaker speeches
We next apply our algorithm to six different corpora: speeches by policymakers from the ECB, Federal Reserve, IMF, European Commission, European Council and European Parliament, to develop some key stylized facts about the nature of communication by policymakers.5
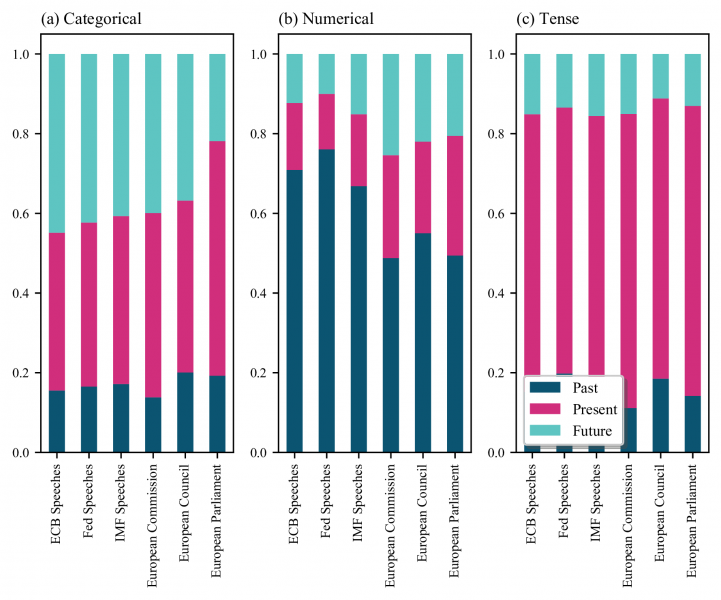
Using the output of SUTime and TMV, we calculate the relative frequency of references to the past, present and future by type of tag (categorical, numerical and tense) and by policymaking institution. Figure 3 shows that policymakers use numerical references predominantly to talk about the past, particularly so for the two central banks in the sample. This may reflect that central bankers often discuss macroeconomic data releases from the recent past. They also frequently put data into historical context to inform their assessment of the economy, which would involve further references to the past.
Categorical references are more skewed toward the future than the other tags. Central bankers have the greatest future skew among the institutions, which may reflect communication about concepts such as “the medium term horizon” or “over the coming years”, often used when providing their projections for the economy or expressing expectations about future policy. The temporal distribution among tense tags is remarkably similar across corpora. This likely reflects a general feature of the English language as used in practice, with the share of present tense references typically taking a value of approximately 70%.
Figure 3: Past, present and future orientation across corpora
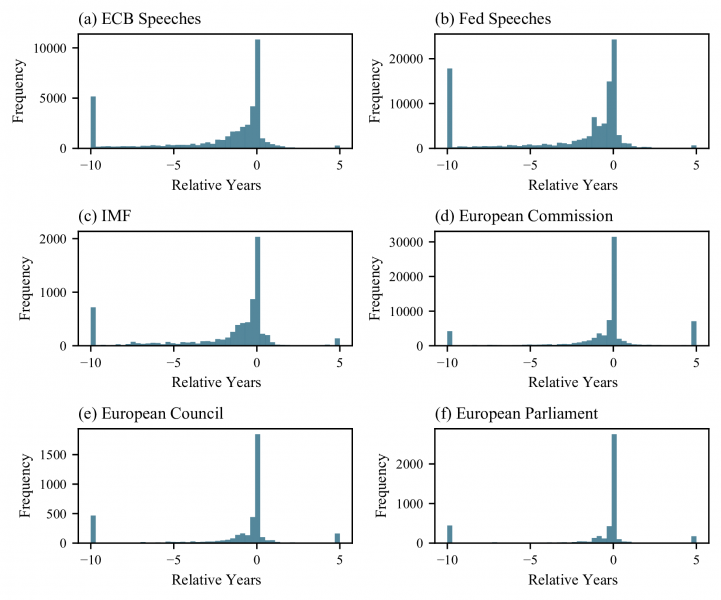
Finally, one additional advantage of our numerical measure is that we can examine the time horizon of communication. Figure 4 shows histograms of numerical temporal references across corpora. We see clearly, in line with what we have shown in Figure 3, that the distributions have a negative skew highlighting the past bias of numerical references. In addition, we notice that central bank speeches have a tendency to focus more on the fairly recent past, likely providing markets with the central bank’s assessment of incoming economic data. This result is in line with the findings of Byrne et al. (2023a), in which monetary policymakers can generate market responses by discussing their evaluation of past data. By contrast, speeches from institutions such as the European Commission seem to concentrate more on the present when making categorical references. While we believe stylized facts such as these are helpful for establishing the broad terrain of temporal references, our results represent a useful starting point for an expanded research effort to develop our understanding of the implications of temporal orientation.
Our study highlights and synthesizes cutting edge methods from the NLP field that are devoted to quantifying references to time. Quantification of communication related to time is applicable to many areas in economics, including discussions of risk, asset pricing, economic or financial cycles, growth, social discount rates, and the evaluation of policy change. We provide an overview of the tools available to quantify time, propose an approach to integrate information from multiple taggers, and document important stylized facts about the nature of the patterns of temporality in policymaker speech. We hope future work will deepen and hone our understanding of the Time dimension of text, in a complementary manner to our existing understanding of Topic and Tone.
Figure 4: Histograms of numerical temporal references across corpora
Apel, Mikael, Blix Grimaldi, Marianna and Hull, Isaiah, (2022), “How Much Information Do Monetary Policy Committees Disclose? Evidence from the FOMC’s Minutes and Transcripts”, Journal of Money, Credit and Banking, 54, issue 5, p. 1459-1490.
Azqueta-Gavaldon, Andres, (2017), “Developing news-based Economic Policy Uncertainty index with unsupervised machine learning”, Economics Letters, 158, issue C, p. 47-50.
Blei, David M., Ng, Andrew Y. and Jordan, Michael I. (2003). “Latent Dirichlet Allocation”. Journal of Machine Learning Research, 3:993–1022.
Byrne, David, Goodhead, Robert, McMahon, Michael and Parle, Conor, (2023a), “The Central Bank Crystal Ball: Temporal information in monetary policy communication”, No 1/RT/23, Research Technical Papers, Central Bank of Ireland.
Byrne, David, Goodhead, Robert, McMahon, Michael and Parle, Conor, (2023b), “Measuring the Temporal Dimension of Text, An Application to Policymaker Speeches”, No 2/RT/23, Research Technical Papers, Central Bank of Ireland.
Chang, Angel X. and Manning, Christopher. (2012). SUTime: “A library for recognizing and normalizing time expressions”, In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), pages 3735–3740, Istanbul, Turkey. European Language Resources Association (ELRA).
Hansen, Stephen, and McMahon, Michael (2016), “Shocking language: Understanding the macroeconomic effects of central bank communication”, The Journal of International Economics, Volume 99, 2016, Pages S114-S133.
Hansen, Stephen, McMahon, Michael and Prat, Andrea (2018), “Transparency and Deliberation Within the FOMC: A Computational Linguistics Approach”, The Quarterly Journal of Economics, Volume 133, Issue 2, May 2018, Pages 801–870.
Istrefi, Klodiana, Odendahl, Florens and Sestieri, Giulia (2021), “Fed’s financial stability concerns and monetary policy” SUERF Policy Brief No. 80.
Nielsen, Finn Arup (2011), “A new ANEW: Evaluation of a word list for sentiment analysis in microblogs”, Proceedings of the ESWC2011 Workshop on ’Making Sense of Microposts’: Big things come in small packages (2011) 93-98.
Parle, Conor, (2022) “The financial market impact of ECB monetary policy press conferences — A text based approach,” European Journal of Political Economy, Elsevier, vol. 74(C).
Ramm, Anita, Friedrich, Annemarie, Loaciga, S. and Fraser, A. (2017), “Annotating tense, mood and voice for English, French and German”, Conference: Proceedings of ACL 2017, System Demonstrations.
Renault, Thomas. (2017). “Intraday online investor sentiment and return patterns in the US stock market”. Journal of Banking & Finance, 84:25–40.
Schmeling, Maik and Wagner, Christian (2019), “Does Central Bank Tone Move Asset Prices?,” CEPR Discussion Papers 13490, C.E.P.R. Discussion Papers.
Schumacher, Gijs, Martijn Schoonvelde, Denise Traber, Tanushree Dahiya, and Erik de Vries (2016), “EUSpeech: A New Dataset of EU Elite Speeches”, Technical Report.
Stone, Philip J., Dunphy, Dexter C., Smith, Marshall S., & Ogilvie, Daniel M. (1966). “The General Inquirer: A computer approach to content analysis in the behavioral sciences”, American Sociological Review 4(4).
See Byrne et al. (2023b), the companion paper to this policy brief, for more details.
For numerical tags, SUTime can be specific about the date being discussed, not just informing us whether it is in the past, present or future.
TMV also identifies mood and voice of a verbal complex but we do not exploit this information.
Note that “Tense*” indicates modified tense addressing the policymaker’s use of verbs such as “expect” or “foresee” to indicate the future.
We make use of the EUSpeech data of Schumacher et al. (2016).



