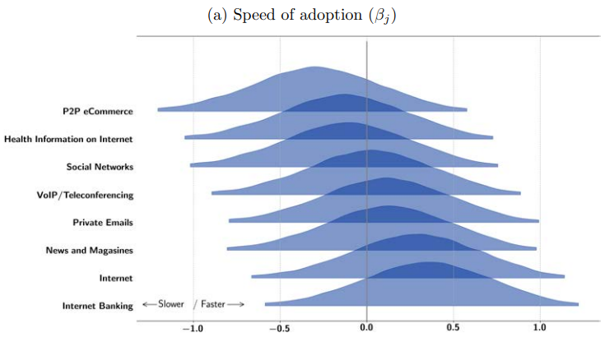
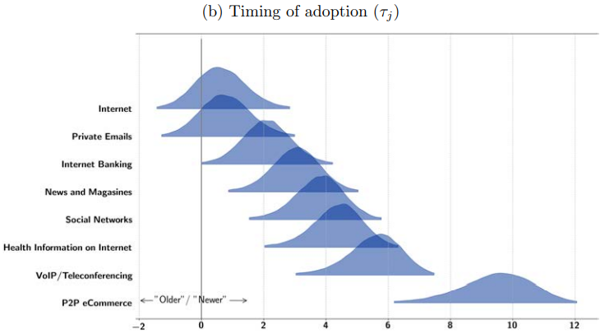
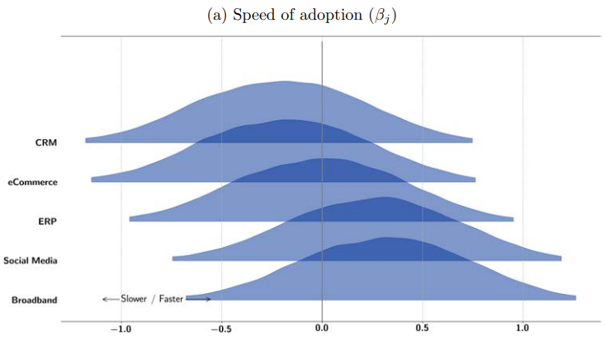
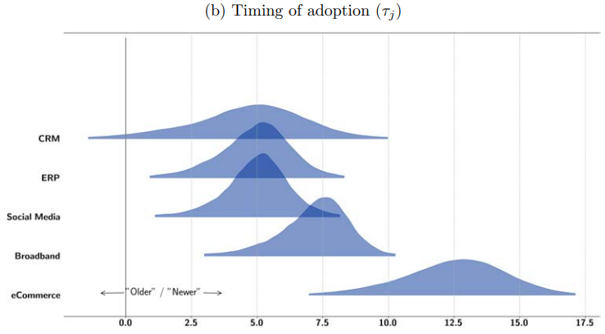
References
Comin, D. and Hobijn, B. (2010) An exploration of technology diffusion. American Economic Review, 100(5):2031–2059, doi: 10.1257/aer.100.5.2031, URL: https://www.aeaweb.org/articles?id=10.1257/aer.100.5.2031.
Mahajan, V., Muller, E. and Bass, F.M. (1990) New product diffusion models in marketing: A review and directions for research. Journal of Marketing, 54(1):1–26, doi: 10.1177/002224299005400101, URL: https://doi.org/10.1177/002224299005400101.
Lenk, P.J. and Rao, A.G. (1990) New models from old: Forecasting product adoption by hierarchical Bayes procedures. Marketing Science, 9(1):42–53, doi: 10.1287/mksc.9.1.42, URL: https://doi.org/10.1287/mksc.9.1.42.
Mansfield, E. (1961) Technical change and the rate of imitation. Econometrica, 29(4):741–766, ISSN: 00129682, 14680262, URL: http://www.jstor.org/stable/1911817